


Data compression paradigm based on omitting self-evident information
Period: 01.11.2022 – 31.10.2025
Funding SOURCE:
- Slovenian Research and Innovation Agency (ARIS)
J2-4458 – Paradigma stiskanja podatkov z odstranjevanjem obnovljivih informacij - The Czech Science Foundation (GA ČR)
23-04622L – Komprese dat založená na vynechání samozřejmé informace – COMPROMISE
Partners:
- University of Maribor, Slovenia
Faculty of Electrical Engineering and Computer Science, Laboratory for Geospatial Modelling, Multimedia and Artificial Intelligence (UM FERI)
- University of West Bohemia in Pilsen, Czech Republic
Department of Computer Science and Engineering (UWB)
Coordinators and Contacts:
- Borut Žalik, David Podgorelec (UM FERI)
- Ivana Kolingerová (UWB)
SOCIAL MEDIA:
Abstract:
Data compression is one of traditional disciplines of computer science, but also one that has made no significant progress in recent decades. It has also failed to keep up with new scientific trends, where new devices collect ever-increasing amounts of highly heterogeneous data. These data are compressed using either general-purpose or domain-dependent methods. The former are well-known lossless solutions from 30 years ago (e.g., RAR or ZIP). They achieve generality by handling a data stream on the level of bytes, ignoring potential higher-level relations in the data. The domain-dependent methods are lossy, near lossless, or lossless. Lossy methods operate by transforming the data into frequency space, performing the quantization there, and encoding the remaining values in a lossless manner, whereby the lossless part is typically domain dependent as well. Near lossless and lossless methods are typically prediction based. However, the predictions are made from a narrow spatial and/or temporal context, which reduces the efficiency. Most methods are symmetric, which means that decoding is performed by the same pipeline as encoding, only in a reversed order. The disadvantage is that the time complexity of decoding is the same as that of encoding. Finally, each type of data requires a specific solution that is not transferable to other types of data.
The overall objective of COMPROMISE is the development of a new data compression paradigm that is based on the investigation of advanced prediction methods with incorporation of features and restoration methods. Furthermore, the developed data compression methodology is supposed to be largely domain independent and asymmetric. The COMPROMISE paradigm is being achieved by consistently meeting the following specific project objectives:
- SO1: To develop a universal data compression methodology with a unified taxonomy of features from diverse domains, and a common framework for lossless, near lossless, and lossy compression.
- SO2: To upgrade the prediction of original data by integrating the techniques of feature selection and data restoration.
- SO3: To improve the compression ratios in lossless and near-lossless mode in comparison with the existing approaches.
- SO4: To improve the accessibility and reusability of features and feature-based restoration.
- SO5: To deliver a verification environment for hypothesis testing in four pilot domains: raster images, digital audio, biomedical signals, and sparse voxel grids.
- SO6: To disseminate the project results.
The following hypothesis is being examined within COMPROMISE to demonstrate the universality, domain independence and efficiency of the methodology:
Hypothesis: The universal methodology of lossless or near lossless data compression, which will be based on unified feature taxonomy and restoration methods, will be more efficient than the existing compression procedures for raster images, digital audio, biomedical signals, and sparse voxel grids.
The pilot domains from SO5 differ in both the data dimensionality and dynamism, while addressing two human perceptual systems – vision and hearing. The UM FERI team predominantly deals with images and audio while biomedical signals are reserved for UWB. The last pilot domain, sparse voxel grids, expectedly requires tight cooperation and nearly equal efforts from both groups. The methodology is being implemented with a unified platform, expected to achieve better lossless and near lossless compression ratios than existing domain-dependent methods and, thus, setting the foundation for a new generation of data compression methods.
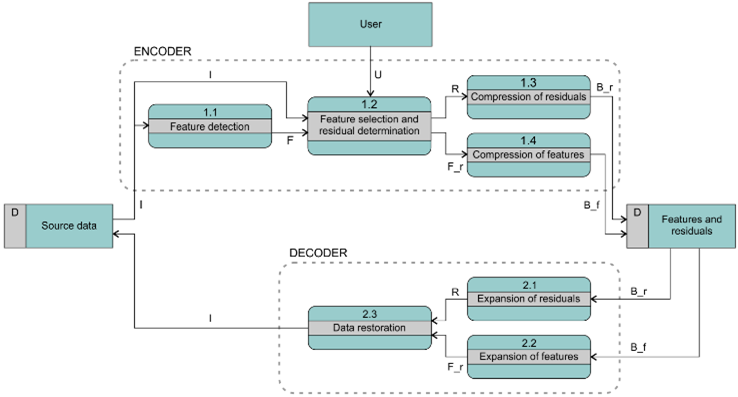
Figure 1: COMPROMISE software platform concept.
The COMPROMISE paradigm will be verified by developing the software platform from Fig. 1. The encoder accepts the input data stream I and detects its features F (process 1.1). In the next module (1.2), the set of detected features is reduced through optimisation of the output data size and restoration abilities. The user-defined compression mode and allowed tolerances are also considered within this module (data flow U). This iterative optimisation process also incorporates the data restoration method (the same module 2.3 is used by the decoder). The described module 1.2 outputs two data streams: the reduced set of features F_r and the residuals R. The latter contain the differences between the data in the input stream I and the most recently restored data generated within the module. F_r and R are then encoded by a lossless data compression method (1.3 and 1.4). The resulting bit streams B_r and B_f are then stored in the file. Decoding of the compressed data in the bottom part of Fig. 1 is significantly simpler. The decompressed data streams F_r (2.2) and R (2.1) are used to restore the data stream I (2.3).
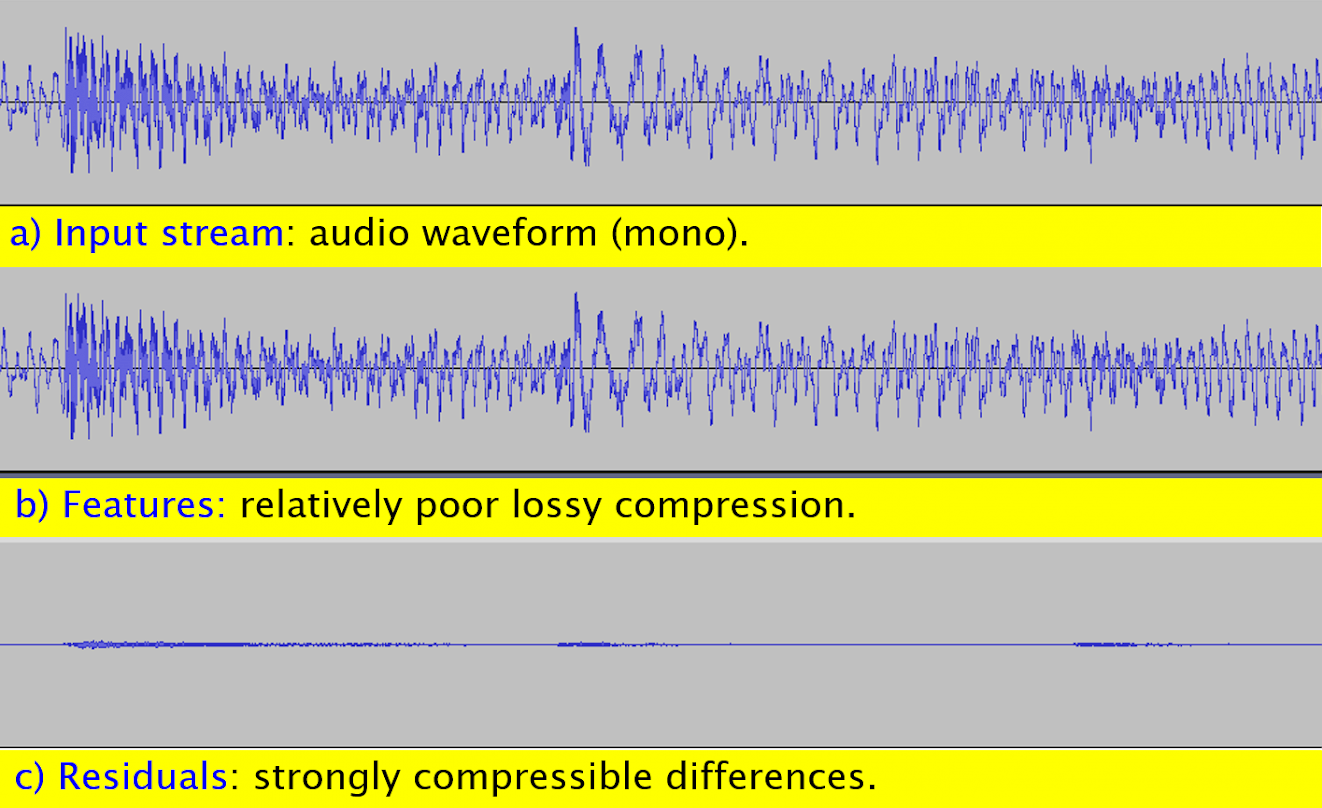
Figure 2: A test case in the digital audio domain (a) with the selection of a rich feature set (b) and consequently with well compressible residuals (c).
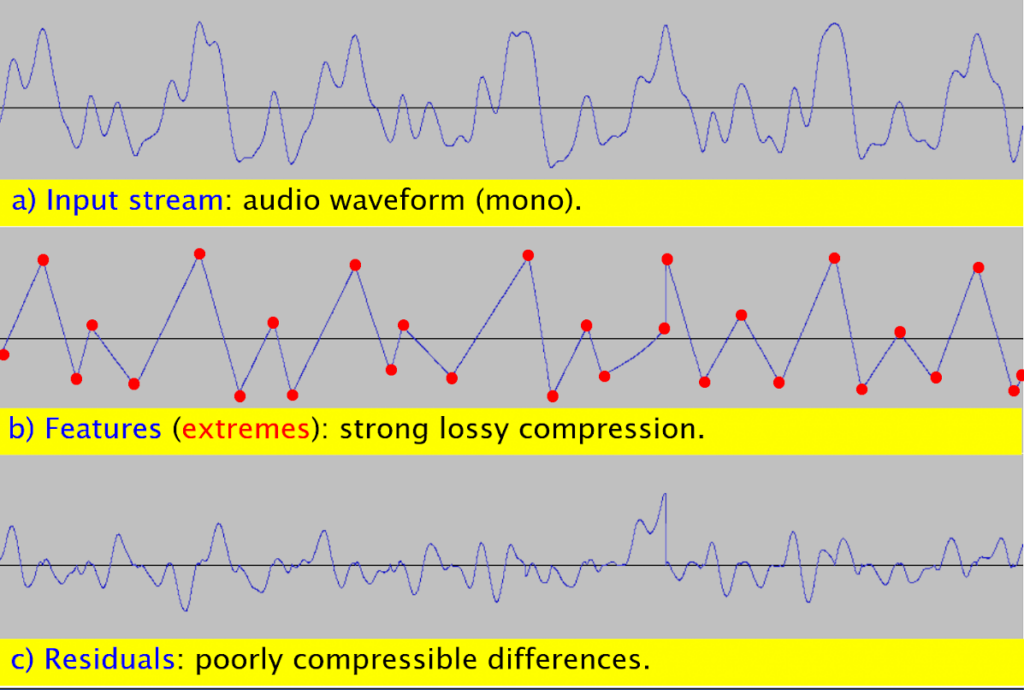
Figure 3: A test case in the digital audio domain (a) with the selection of a more modest feature set (b) and consequently less compressible residuals (c).
The COMPROMISE data compression is a compromise between a rich feature set (Figure 2b), which can take up a lot of space but results in mostly small and well compressible residuals (Figure 2c), and a more modest feature set (Figure 3b), which takes up little space but results in larger and less compressible residuals (Figure 3c). Thus, the more memory-intensive B_f (Figure 1) generally means a saving in B_r and vice versa. Achieving the optimal compromise is the main role of feature selection (block 1.2 in Figure 1).
This project has received funding from the Slovenian Research and Innovation Agency under the “Public Call for co-financing of research projects in 2022”. Research grant J2-4458.

