EDGE - Data Mining Analytical Engine
From 2014 until 2015
|
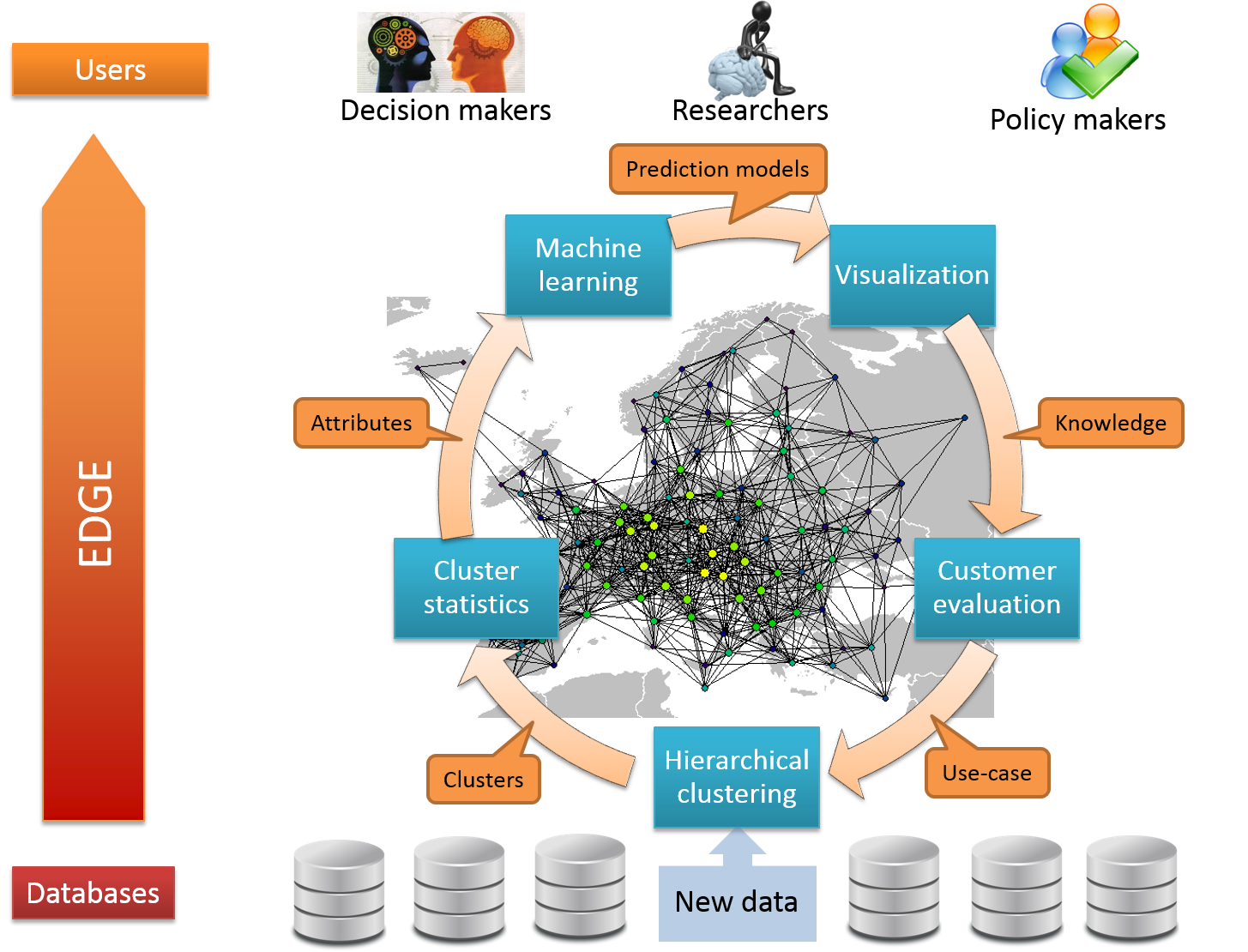
EDGE is a data mining Application Programming Interface (API) developed by the Laboratory for Geometric Modeling and Multimedia Algorithms at UM FERI for Solverminds Solutions & Technologies (shortly SVM), a software and analytics solution company from India specialized in providing enterprise application and analytical solutions for maritime transport. ProblemIn recent years, we have been witnessing a rapid growth of heterogeneous data sources and streams, which poses new challenges for efficient visualization and knowledge discovery. Recognizing relations and hidden patterns within the data is still a major challenge in the machine learning and data mining. EDGE addresses these problems by decomposing the data into a cluster hierarchy, on top of which various machine learning algorithms fit geometrical surfaces, by which prediction of targeted attributes are made. Moreover, new visualization and statistical analysis is performed over the hierarchy in order to provide better understanding of the underlying relationships within the data. |
 |
Goals
EDGE has the following goals:
-
Develop a data mining platform which is capable of searching for hidden relationships and patterns within large high-dimensional multimodal data.
-
Represent the data in novel ways, understandable and useful to the data owner with new visual and statistical analytics.
-
Provide predictive analytics of the target attributes in support of data driven decision making.
-
Can be integrated easily into many application domains, ranging from the shipping industry, which is among the main SVM priorities, to DNA analysis, where SVM is looking to extend their market.
Solution
Based on the goals, the core solution of EDGE contains the following main functionalities:
-
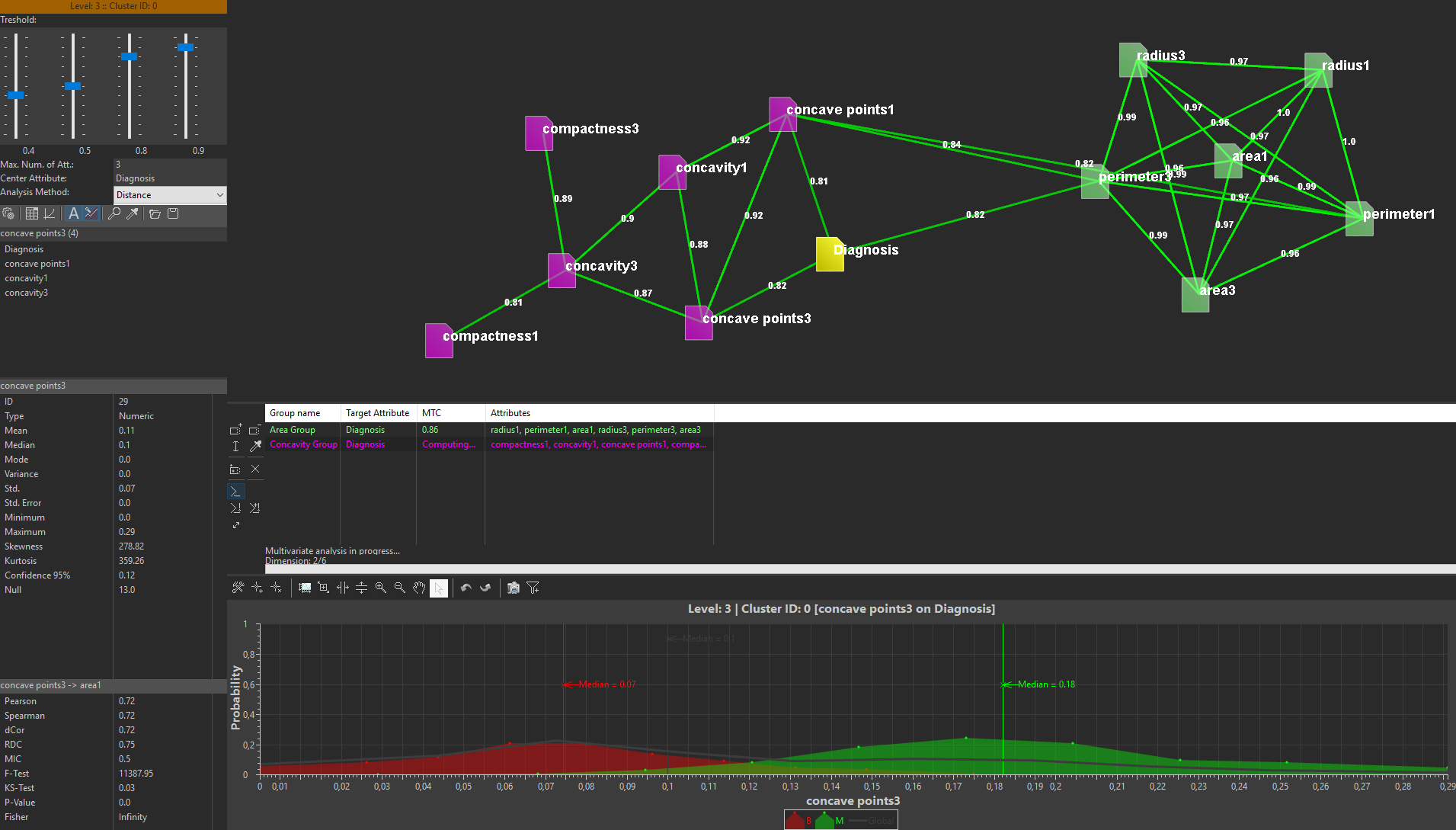
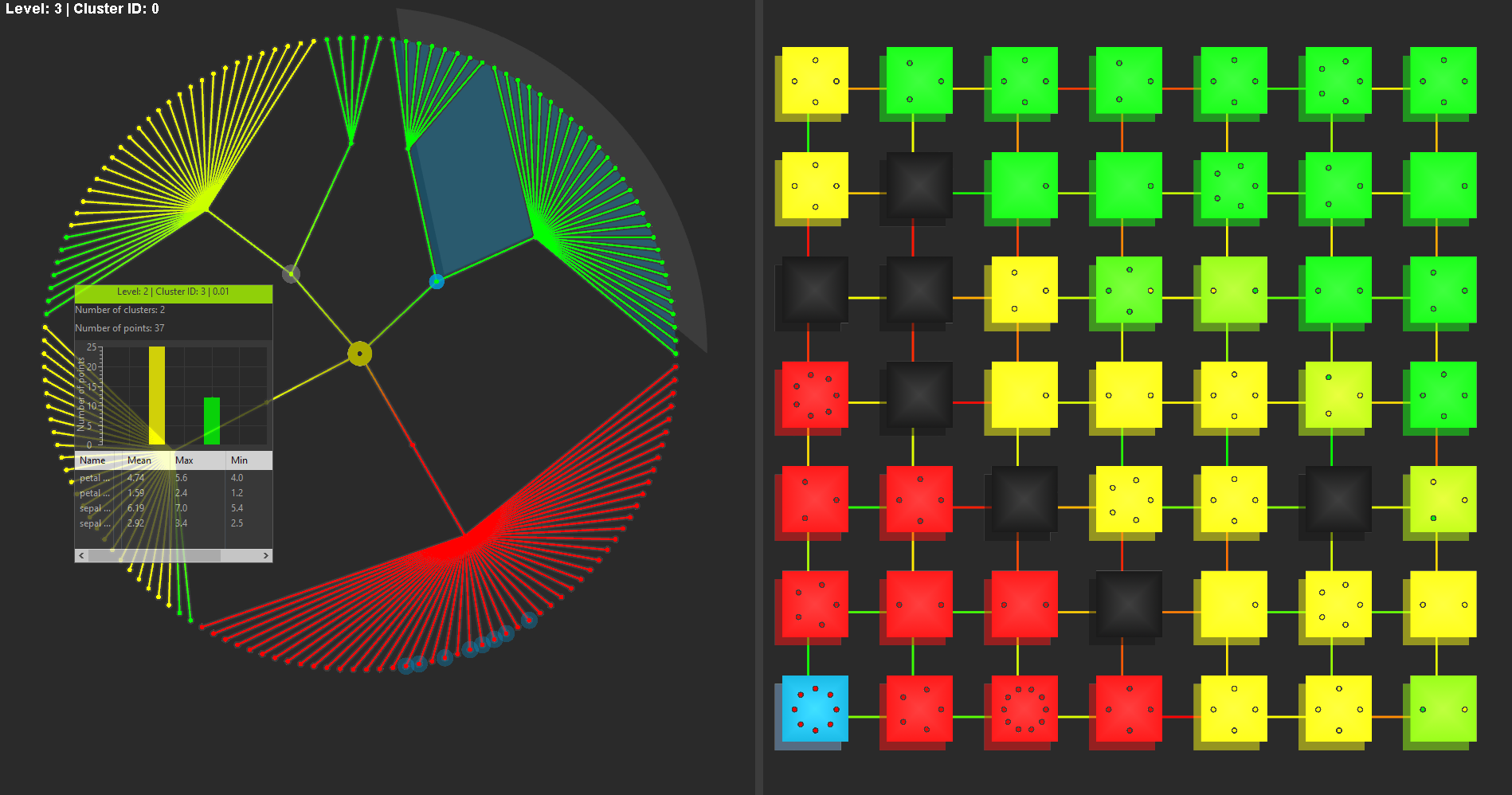
Data preprocessing transforms and consolidates input data into a structured form, appropriate for data mining. This is achieved by organizing the high-dimensional datasets into hierarchical clusters based on geometric similarity between the different substructures present within the data.
-
Data mining combines various machine learning and reasoning methods for finding patterns in very large datasets. Furthermore, prediction of the future trends can be performed based on the current state of the data variables.
-
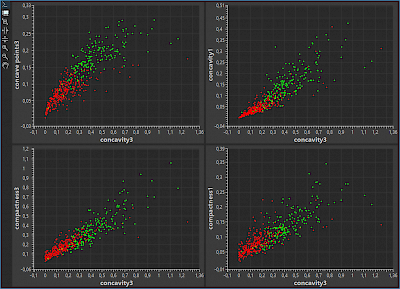
Statistical analytics supports identification of hidden knowledge and patterns. Various statistical tools are offered to the user in order to search for linear and nonlinear correlations between multiple variables.
-
Knowledge representation is realized with various advanced visualization techniques. The visualization is performed in real-time by employing various levels of detail.
 |
 |
 |
 |